| 爬虫 python 正则匹配 保存网页图片 | 您所在的位置:网站首页 › 正则表达式 爬虫 足球 › 爬虫 python 正则匹配 保存网页图片 |
爬虫 python 正则匹配 保存网页图片
|
目录
1. 简介1.1 爬虫1.2 爬虫语言1.3 python库1.4 我的步骤
2. 导入包2.1 代码2.2 requests库
3. 写入文件函数4. 获取图片5. 主函数5.1 代码5.2 说明一下webbrowser
6. 所有代码7. 其他(可以忽略)8. 总结
在这里我只提供的是一种方法,有很多网页有反爬虫的机制,我的代码并不适用所有的网页(百度的图片搜索就不行)
1. 简介
1.1 爬虫
爬虫是指模拟人工访问网站并抓取网站内容的程序。通常爬虫程序由以下几个部分组成: 获取网页内容:爬虫程序需要模拟 HTTP 请求,向目标网站发送请求,并获取网页内容。 解析网页内容:爬虫程序需要对获取的网页内容进行解析,提取出需要的信息,这些信息可能包括文本、图像、视频、链接等。 存储数据:爬虫程序需要将获取到的数据存储到本地或者数据库中,以便进行分析和处理。 爬虫程序通常可以分为以下几个步骤: 确定要爬取的目标网站。 分析目标网站的网页结构,了解网站的 URL 规则和数据格式。 编写爬虫程序,模拟 HTTP 请求,获取网页内容,并解析需要的数据。 对爬取到的数据进行处理,存储到本地或者数据库中。 需要注意的是,爬虫程序需要遵守网站的访问规则和法律法规,不得对网站进行恶意攻击和侵犯他人隐私等行为。此外,为了避免对目标网站的服务器造成负担,爬虫程序应该设置合理的访问频率和访问间隔。 1.2 爬虫语言爬虫可以使用多种编程语言进行开发,常见的有: Python:Python 是目前应用最广泛的爬虫编程语言之一,具有简洁易学、生态丰富、库众多等优点。 Java:Java 是一种通用的编程语言,也可以用来开发爬虫程序。Java 虽然有些冗长,但是其稳定性和跨平台性在爬虫领域表现出色。 JavaScript:JavaScript 常用于前端开发,但也可以用来开发爬虫程序。JavaScript 的优点是在浏览器环境下运行,可以从页面中获取动态生成的内容。 Ruby:Ruby 是一种优雅的编程语言,具有易读易写、面向对象等优点,也可以用来开发爬虫程序。 Go:Go 是一种新兴的编程语言,由于其简单易用、高效等特点,也开始逐渐应用于爬虫编程领域。 不同的编程语言有不同的特点和优缺点,在选择时需要考虑自己的实际需求和个人偏好。 1.3 python库Python 爬虫使用的库非常丰富,以下是一些常用的爬虫库: Requests:用于发送 HTTP 请求,并返回相应的数据,是 Python 中最流行的库之一。 Beautiful Soup:用于解析 HTML 和 XML 文档,可以方便地从网页中提取数据。 Scrapy:一个基于 Python 的高级爬虫框架,可用于抓取大量数据。 Selenium:用于模拟浏览器行为,可以模拟点击、输入等操作,自动化地获取数据。 Pandas:用于数据处理和分析,可以将抓取的数据整理成表格形式进行分析。 Pyquery:用于解析 HTML 和 XML 文档,类似于 jQuery 的语法,可以方便地从网页中提取数据。 Textract:用于提取文本和表格数据,可以自动识别 PDF、Word、Excel 等文档格式。 Scikit-learn:用于机器学习相关的应用,可以对抓取的数据进行分类、聚类等操作。 以上库只是常用的一部分,具体使用时需要根据实际需求选择适合的库。 1.4 我的步骤 导入要使用的包测试是否读取网页查看网页源代码,来写正则匹配打开一个图片,测试保存结合起来,依次匹配,进行保存到文件夹 2. 导入包 2.1 代码 import os import requests import webbrowser import sys import cv2 import re 2.2 requests库我使用的库是requests Requests 是 Python 中非常流行的 HTTP 请求库,用于发送 HTTP 请求并获取响应。它提供了简单易用的 API,可以轻松地发送 GET、POST、PUT 等请求,还可以添加请求头、发送 cookie 等。以下是 Requests 库的基本使用方法: 安装 Requests 库:在命令行中输入 pip install requests 即可安装。 导入 Requests 库:在 Python 文件中使用 import requests 导入库。 发送 HTTP 请求:使用 requests.get(url) 发送 GET 请求,使用 requests.post(url, data) 发送 POST 请求。其中,url 是请求的网址,data 是请求参数。 获取响应:使用 response.text 获取响应内容,使用 response.status_code 获取响应状态码。 添加请求头:使用 headers 参数添加请求头,如 requests.get(url, headers=headers)。 发送 cookie:使用 cookies 参数添加 cookie,如 requests.get(url, cookies=cookies)。 超时设置:使用 timeout 参数设置超时时间,如 requests.get(url, timeout=5)。 以下是一个使用 Requests 发送 GET 请求的示例: import requests response = requests.get('https://www.baidu.com') print(response.text)以上代码会发送一个 GET 请求到百度首页,并获取响应内容打印出来。注意,这里的 response.text 是获取响应内容的方法。如果要获取二进制数据,可以使用 response.content。 3. 写入文件函数代码: # 写入文件函数 def down_pic(url, filename): #定义一个函数,用于下载网络图片,参数url为图片对应的url地址,filename为爬取图片名字 r = requests.get(url) # 获取网页内容 path = './picture' # 爬取图片待存储目录 if not os.path.exists(path): # 判断桌面是否有一个名称为“图片”的文件夹,如果没有,就创建它 os.mkdir(path) # 爬取图片 with open(path + '\\' + filename, 'wb') as f: f.write(r.content) # 以二进制形式写入文件 f.close # 关闭文件这里的url不是网页地址,是图片地址。 我们可以打开一个含有图片的网页 在空白处右击进行检查或者按Ctrl+shift+I 选择你想查看的图片 复制地址 新开一个网页,在最上面,输入这个地址,进入地址 代码: def get_web(url): header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36', 'Cookie':'*****'#cookie需要你先自己在浏览器登录百度账号,再按f12就有了 'Accept':'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9'} response = requests.get(url,headers=header) # print(response) # print(response.content.decode()) text = response.content.decode() # 获取文档 # 存一下看看 path = "./text.html" file = open(path,'w',encoding="utf-8") file.write(text) file.close() # 接下来进行正则匹配 r = r"data-original=\"(.*?)\"" fill = re.findall(r,text) print(fill[0]) # 命名 a = "" for i in range(len(fill)): url = "https:" + fill[i] a = str(i) +".jpg" down_pic(url,a) a = ""在你要爬虫的页面,按ctrl+shift+I进行检查的console栏,输入alert(document.cookie) 这样就获取了你的cookie 在这个代码里,我将获取的text保存到html文件里了,这样方便查看。 最主要的部分是正则匹配,可以通过查看文档来考虑图片地址的匹配方式。 5. 主函数 5.1 代码 if __name__ == '__main__': url = 'https://sc.chinaz.com/tupian/gudianmeinvtupian.html' # 图片对应的url地址 # webbrowser.open(url) # 打开网页 # 获取文件文档,然后匹配文件 get_web(url)这里我爬虫的网页是一个含有图片的免费下载的网站,对于别的网站我也没有试过。 https://sc.chinaz.com/tupian/gudianmeinvtupian.html webbrowser 是 Python 内置的标准库,可以用来在默认浏览器中打开指定的 URL。webbrowser.open(url) 方法接收一个 URL 参数,它会自动打开系统默认浏览器并在其中打开指定的 URL。 下面是一个示例: import webbrowser url = "https://www.baidu.com" webbrowser.open(url)运行以上代码后,系统默认浏览器会打开百度的首页。如果系统中有多个浏览器,那么会打开默认浏览器。 webbrowser 库还提供了其他一些方法,例如 open_new() 和 open_new_tab(),它们分别用来在新窗口和新标签页中打开 URL。例如: import webbrowser url = "https://www.baidu.com" webbrowser.open_new_tab(url)运行以上代码后,系统默认浏览器会在新标签页中打开百度的首页。 6. 所有代码 ''' Descripttion: 存储网络上的图片,算是做了一些吧 version: 版本 Author: YueXuanZi Date: 2023-05-30 14:52:30 LastEditors: YueXuanZi LastEditTime: 2023-05-31 20:53:50 Experience: 心得体会 ''' import os import requests import webbrowser import sys import cv2 import re # 写入文件函数 def down_pic(url, filename): #定义一个函数,用于下载网络图片,参数url为图片对应的url地址,filename为爬取图片名字 r = requests.get(url) # 获取网页内容 path = './picture' # 爬取图片待存储目录 if not os.path.exists(path): # 判断桌面是否有一个名称为“图片”的文件夹,如果没有,就创建它 os.mkdir(path) # 爬取图片 with open(path + '\\' + filename, 'wb') as f: f.write(r.content) # 以二进制形式写入文件 f.close # 关闭文件 def get_web(url): header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36', 'Cookie':'***',#cookie需要你先自己在浏览器登录百度账号,再按f12就有了 'Accept':'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9'} response = requests.get(url,headers=header) # print(response) # print(response.content.decode()) text = response.content.decode() # 获取文档 # 存一下看看 path = "./text.html" file = open(path,'w',encoding="utf-8") file.write(text) file.close() # 接下来进行正则匹配 r = r"data-original=\"(.*?)\"" fill = re.findall(r,text) print(fill[0]) a = "" for i in range(len(fill)): url = "https:" + fill[i] a = str(i) +".jpg" down_pic(url,a) a = "" if __name__ == '__main__': url = 'https://sc.chinaz.com/tupian/gudianmeinvtupian.html' # 图片对应的url地址 # webbrowser.open(url) # 打开网页 # 获取文件文档,然后匹配文件 get_web(url) 7. 其他(可以忽略)不是专门学习爬虫,有了想法就去做了,遇到困难就解决困难。多去尝试一下,哈哈哈哈哈。 就当是给自己玩一个游戏吧,感受一下键盘敲击的快乐,在头脑风暴中沉醉。 这是很重要的一个体验,接触多了有趣多了。 8. 总结还算顺利,都还可以,CSDN里基本上都有我想要找到的,方法总比苦难多,以后要不要学习用JAVA或者javascript等别的一些语言进行爬虫啊,还在考虑,哈哈哈哈。学习爬虫是因为做一下机器视觉实验或者机器学习的时候没有素材,后来发现,没有网上人家自己搜集的数据集好。就当是一个体验吧,哈哈哈哈。 最后把开始那张照片放在这吧,欢迎大家在评论区交流。
|
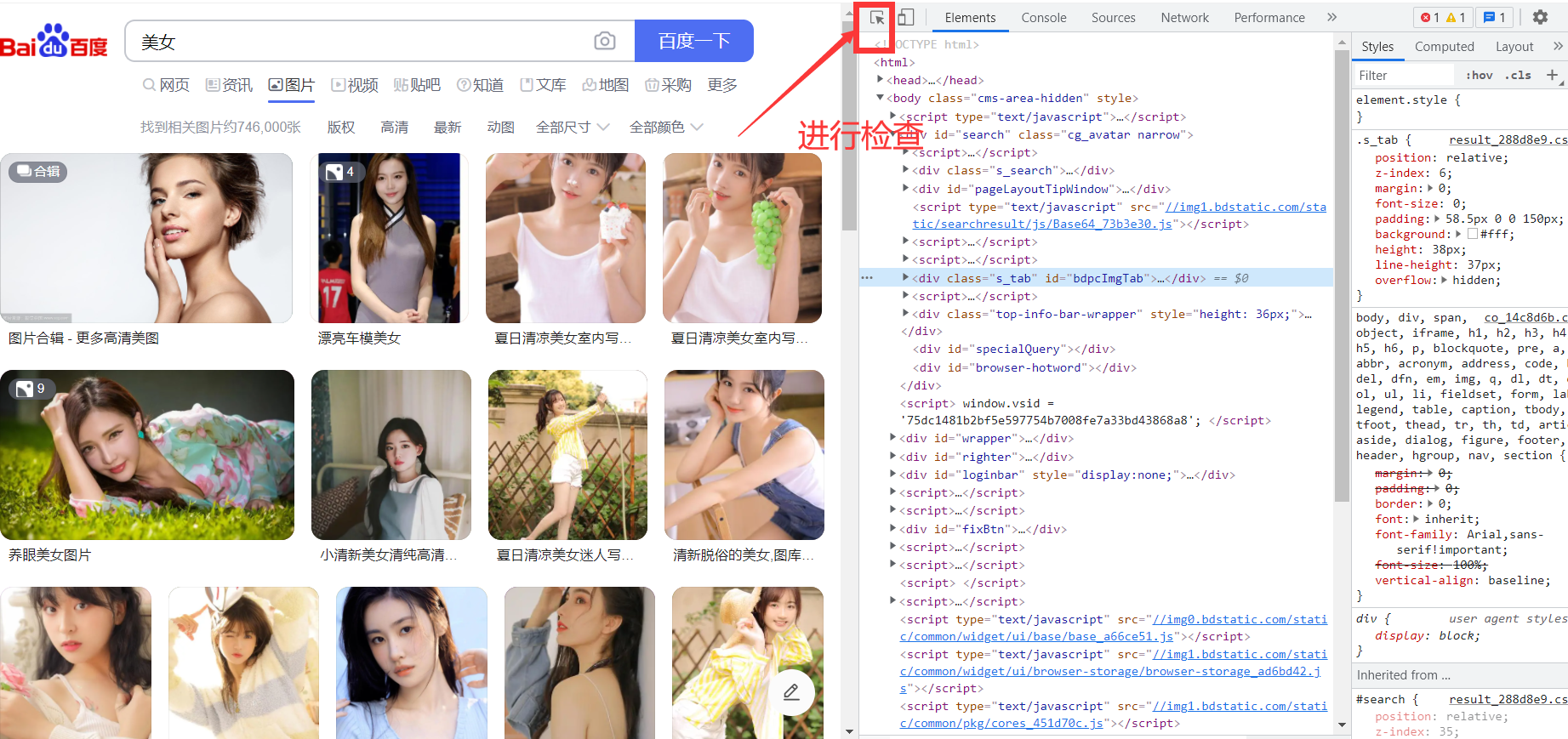
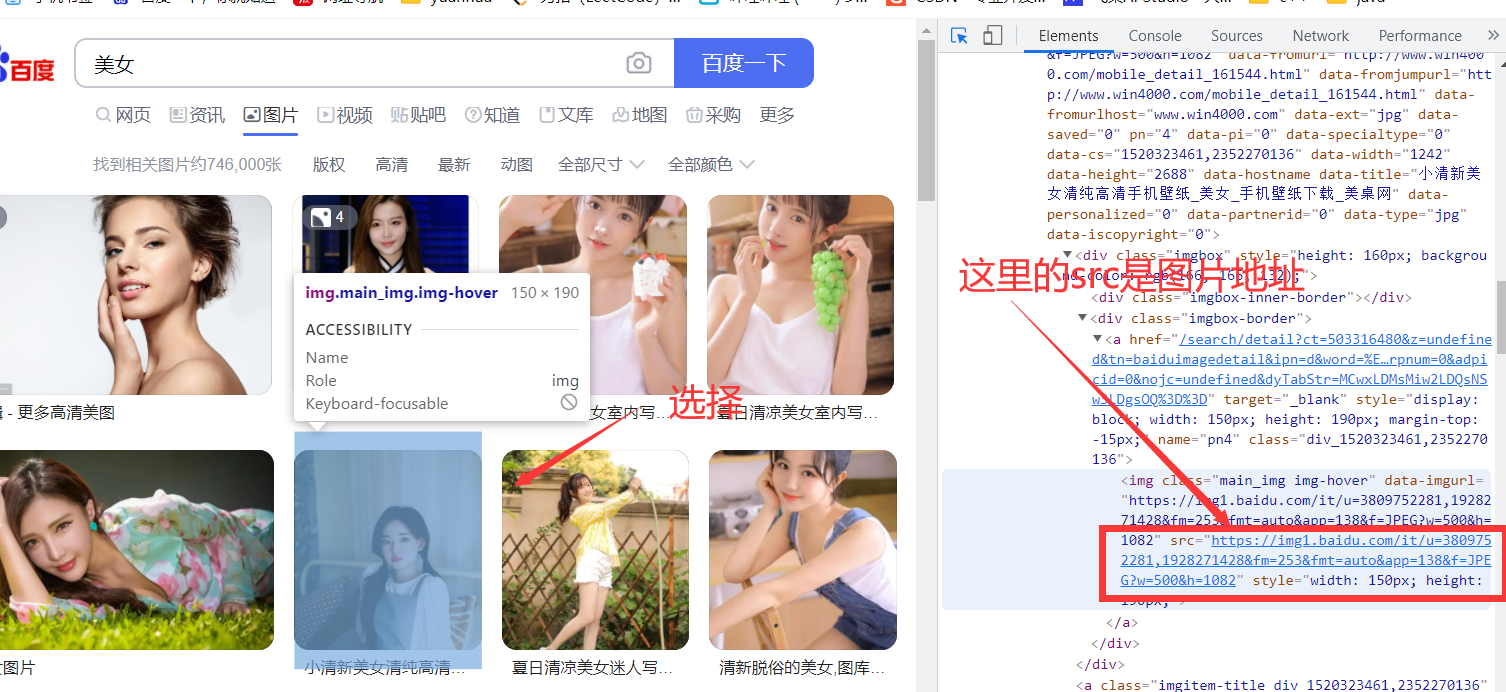
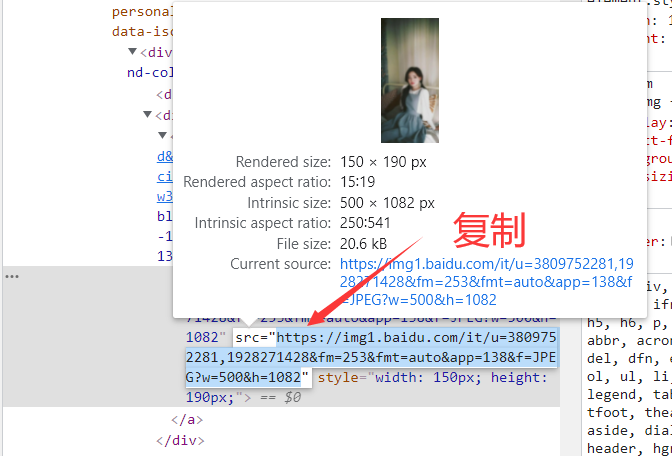

 这里的地址就是网页地址 右击可以选择地址进行保存,嘻嘻!!!
这里的地址就是网页地址 右击可以选择地址进行保存,嘻嘻!!!

【本文地址】